From Lift-and-Shift to Learn-and-Leap

A migration playbook that pays off inside the quarter
Lift and shift sounds safe. Copy your stack to the cloud and keep going. Many teams do it and discover the same thing. Costs rise, outages move to new places, and the promised speed never shows. The issue is not the cloud. It is moving a mystery.
Learn and leap solves that. Learn how the system really behaves. Leap only where the data says value is high and risk is low. Migrate the smallest slice that matters, keep interfaces stable, and prove parity before users notice a change.
Why lift and shift disappoints
Server habits in a services world
Jobs expect local shares, machine schedulers, and registry reads. The cloud charges for these habits and gives little back.
Unknown bottlenecks move with you
A monthly stall on premises becomes a weekly incident at scale.
Spend goes up without faster delivery
If deploys, tests, and rollbacks do not improve, you only changed the data center.
What learn and leap means
Learn is a short discovery that produces facts, not opinions.
Leap is a small migration that proves sameness, then takes traffic in calm steps.
The learn phase
Build a living map
List services, jobs, databases, queues, file paths, and partner endpoints. Overlay runtime evidence from logs and traces. Mark hot paths by traffic and revenue. Mark cold paths that never run.
Tag anchors
Find local file assumptions, 32 bit components, machine scheduled tasks, WCF or SOAP edges, and forked libraries that drifted from upstream.
Pick one slice
Choose a bounded capability with clear inputs and outputs. Good first moves include PDF generation, address validation, discount rules, or a reporting extractor.
Write a parity plan
Collect five to ten request and response pairs. Define what must match and what can differ. This keeps tests clear and cutovers calm.
Time box learn to two weeks so evidence drives decisions.
The leap phase
Mirror reality
Stand up a green lane that shares config, secrets, and data shape with production. Bring the slice up on the target platform. Use containers, managed storage, and managed schedulers where possible.
Replay real traffic
Feed the green lane with a window of production requests. Compare outputs to the baseline. Fix drift in the mirror, not in front of users.
Shift traffic in steps
Start at five percent. Watch error rate and p95 latency from one dashboard that shows both lanes. Increase to twenty five, then fifty, then full. Keep a one click rollback.
Retire debt immediately
Remove server shares, patch scripts, and forked clients as the slice moves. Record hours removed and incidents avoided.
Publish the win
Share three numbers after cutover. Incidents on the path, cost to serve the path, and time to deploy a change. Make the story repeatable.
A quick example
A billing team planned to rehost a monolith. During learn, the map showed invoice PDFs drove the biggest CPU spikes and relied on a server share and a forked library. They chose PDF generation as the first slice and wrote a parity plan with five invoice shapes and a body checksum.
In the green lane they moved PDFs to a container and object storage, restored the upstream library, and replayed a day of real requests. Two mismatches came from a font change and a timestamp in a footer. Fixed in hours. Canary began at five percent. At twenty five percent a rare template failed for non ASCII names. Fixed in the mirror. The path went to one hundred percent the next day.
They retired the share, deleted a night script, and flattened month end spikes. The win was visible in two weeks. Lift and shift was no longer the plan.
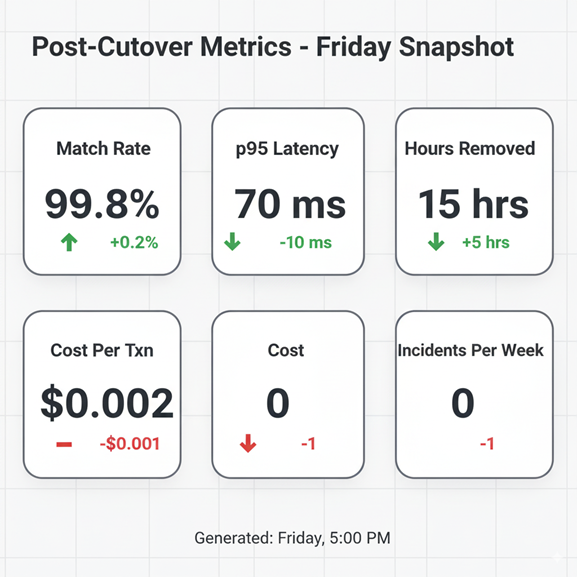
What to measure so leaders stay on side
- Match rate in mirror and canary
- p95 latency and error rate on the new path
- Hours of manual work removed
- Cost per transaction for the slice
- Incidents per week on the modern path
Share the same chart every Friday. Consistency builds trust.
Where LensHub helps
LensHub accelerates learn with a living map, anchor tagging, and a ranked list of first slices. It generates parity plans from real traffic, runs the mirror, compares outputs, and watches canary health. It also keeps a savings ledger that tracks hours removed, incidents avoided, and unit cost gains. Your team stays in control. Guesswork goes away.
Ready to Learn and Leap from Legacy?
Want a two week learn and leap starter plan for your system? Ask for a LensHub migration brief with your first slice, parity tests, and a cutover route you can ship.